
Goroutines to improve Aurora Serverless V2 performance via Lambda
Inserting 10k records in <30 seconds!

This was perhaps the first time I ever experienced the trill of using Goroutines. I enjoyed writing multi-threaded applications in Java back in 2011, and later I spent my time cherishing the async programming paradigm. Having practicing Golang for quite some time now, I now believe that I am spending my time in a good way.
The problem by itself is very simple - insert 10k records in a relational database in least amount of time and in an inexpensive way. The time and money aspect made it more tricky.
What made it tricky?
We have written most of our Lambdas using Golang. That is not a problem. In a super-cloud-native environment, where we boast our adoption of serverless technologies and serverless-first approach - doing such database transactions raises the eyebrows to say the least.
I wrote a simple Go function to do this job in a basic for loop. The data source was an external API which had it’s own issues with pagination. The pagination was sorted, but then now this simple for loop took around 1.5 hours to sequentially insert these 10k records.
As soon as the execution passed 15 mins mark, I immediately thought of Lambdas, and I said to myself - this won’t work. Additionally, to keep this data fresh there were talks of running this function every 5 mins or less.
At this point, I seriously considered using EC2 instance or a Fargate container.
We have used DynamoDB (NoSQL) databases for other purposes, where we insert few records every 30 mins - and few records are manageable anywhere. But DynamoDB does not properly offer a full sorting since it is always dependent on the partitions. So for this case, the choice was to use Relational DB by using RDS service - perhaps Aurora. This was the part where we thought of the money. Provisioning a RDS database would easily burn USD 500 every month.
Aurora Serverless V2 to the rescue
We noticed that Aurora Serverless V2 was recently launched, and we could very well use it. The beauty of serverless technologies is that they scale up and down as much and as and when needed. I have heard the reports of it proving to be very expensive in certain cases and would not be a good idea yet. But I am hopeful and at the same time worry-less since the same code would work for any other Postgres DB hosted on RDS, if at all we had the need to change.
So the money part was sorted.
What about the time?
I realised I am using Golang to write this function. Thats when it clicked to use Goroutines. This is an ideal case for the same. The resources on my local system, as well as the database connection throttling weren’t any issues - since my system hosts 8 cores, and the database is serverless - so both have the infra to scale.
I implemented Goroutines correctly, but at a wrong place. The logs on the terminal screen moved with the same speed, as if there were no workers created by goroutine. Soon, I realised my mistake and placed the goroutine logic at right place. I initally tried with 4 routines, which would have reduced the time by 4 - meaning 22.5 minutes.
But I was a bit impatient and increased the count to 8. I could see the logs in the terminal were flowing at a much faster rate. That is when I realised - this works! But 11 minutes still were too much for a Lambda function. Then I terminated the process again, took a leap of faith, and increased the count to 20.
My only expectation was to reduce this time to less than 5 minutes. The program ran, and before I could check, it had ended within 3 minutes on my local system! Much happy.
Time for Lambda
I later changed the code to set the number of routines to be based on number of CPU cores available on any given system. I also used the same parameter to divide the load across those routines evenly.
workerCount := runtime.NumCPU() * 4My target was to run 4 routines on each CPU core. My local system supported 8 cores, so it was capable of running at least 32 routines. But I was fine with 3 minutes, after all it was all local execution. I was still skeptical about Lambda.
I deployed the code to Lambda and gave it a try. It failed after 25 seconds. Obviously - I thought to myself - this would take at least 3 mins. So the default value which was set to 25 seconds was increased to 5 mins. I also noticed, only 2 CPUs were assigned, due to which only 8 workers were created - against 20 on my local system.
The application by itself is not memory intensive, and Lambda does not let us allocate the number of CPUs directly. After reading some documentation, I increased the memory allocation to 2 GB from the default 128 MB, in the hopes that enough CPUs would be allocated to run the routines in shortest amount of time. 128 MB of memory allocates 2 CPUs, which translates to 8 workers. This scared me a bit.
Ran the application again, and the run was completed successfully in 25 seconds! Wait what? The Lambda function was still using 2 cores and 8 workers! Wait a minute! My first impression was that of a failure and I thought this was just impossible.
How network latency affects!
I went to check the database - everything looked good. I deleted all the records from the table just to be sure. Reduced the memory allocation back to 128 MBs since it did not make any difference. Reduced the execution time to 2 mins on the Lambda function.
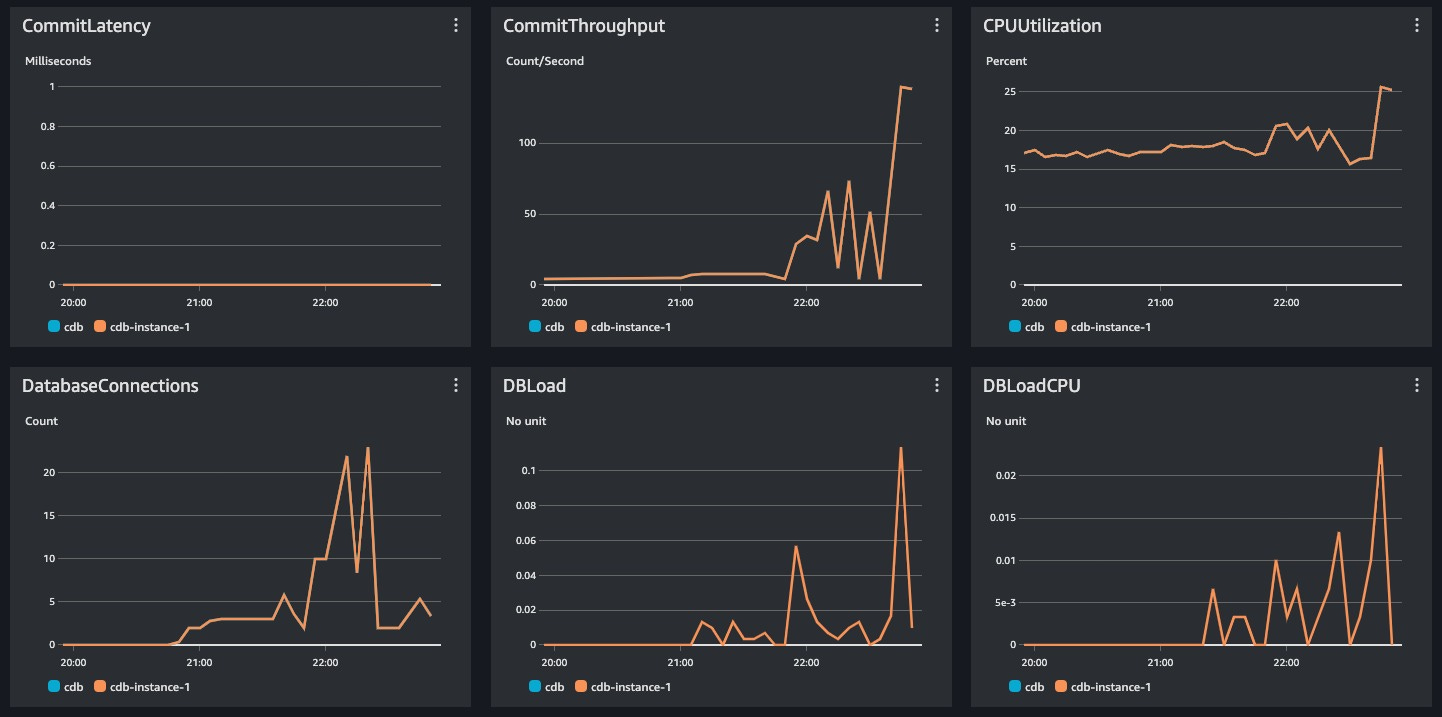
Ran the function again, and it worked just fine with all the 10k records being created in just 30 seconds.
I later realised, perhaps the database and Lambda functions reside in same DC and same VPC, the time taken by the write operations to be executed is much lower as compared to my laptop sitting somewhere on the internet!
The last one was a good week, and I am not scared of database operations anymore for the next week. Leaving you with some DB monitor graphs of this story.
Sumeet N.